728x90
JPA
- DTO를 사용하는 이유
- 실무에서 데이터를 한 번 요청할 때 많은 비용이 든다. 비용을 줄이기 위해 요청 횟수를 줄여야하는데 JAVA에서는 반환 값을 여러개로 할 수도 없다. 이것을 해결하기 위해 요청에 대한 모든 데이터를 DTO에 담아 반환한다.
- DTO란 무엇인가, VO와의 비교
- N + 1 문제에 대해 설명
- N+1문제
- 연관관계가 설정된 엔티티를 조회할 때, 조회된 데이터의 개수만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 된다
- FetchType을 Eager에서 Lazy로 바꾸면 될까?
- 아니다. FetchType을 Lazy로 바꾼다고 해도 달라지는 건 없다. 단지 N+1 문제 발생 시점을 연관관계 데이터를 사용하는 시점으로 미룰지, 아니면 초기 데이터 로드 시점에 가져오는지의 차이가 있는 것 뿐이다.
- N + 1 문제 발생 원인
- findAll()은 무조건 ‘SELECT * FROM 테이블이름’ SQL만 실행하기 때문에 연관관계 데이터를 무시하고 오로지 해당 엔티티 기준으로 쿼리를 조회한다. 연관된 엔티티 데이터가 필요할 경우, FetchType으로 조회를 별도로 호출하게 된다.
- 해결 방법
- 대표적으로는 Fetch join이 있다. 하지만 JpaRepository에서는 제공하지 않아 JPQL을 작성해야 한다.
- Fetch join에는 단점이 있다. FetchType을 사용할 수 없고, 페이징 쿼리를 사용할 수 없다. 페이징을 사용할 수 없는 이유는 하나의 쿼리로 필요한 모든 데이터를 가져오기 때문에 페이징 단위로 가져오는 것이 불가능하다.
- N+1문제
- Entity를 설계할때 주의할 점
- 가급적 setter 사용 금지
- 변경 포인트가 많아 유지보수가 어렵다
- 모든 연관관계는 지연로딩(FetchType.Lazy)로 설정
- 즉시로딩(Eager)은 예측이 어렵고 어떤 쿼리가 실행될지 추적하기 어렵다.
- 컬렉션은 필드에서 초기화
- 컬렉션은 필드에서 바로 초기화하는 것이 안전한다
- 하이버네이트는 엔티티를 영속화할 때 컬렉션을 감싸서 하이버네이트가 제공하는 내장 컬렉션으로 변경한다. 만약 get하는 임의의 메소드에서 컬렉션을 잘못 생성하면 하이버네이트 내부 메커니즘에 문제가 발생할 수 있다.
- 테이블, 컬럼명 생성 전략
- 스프링부트에서 하이버네이트 기본 매핑 전략을 변경하기 때문에 실제 테이블 필드명과 다르다
- 하이버네이트 : 엔티티의 필드명 그대로 테이블의 컬럼명으로 사용
- 스프링 부트 신규 설정 (엔티티(필드) 테이블(컬럼))
- 카멜 케이스 언더스코어(memberPoint member_point)
- .(점) _(언더스코어)
- 대문자 소문자
- 핵심 비즈니스 로직은 데이터를 가지고 있는 쪽에 구현
- 객체 지향적인 코드를 위해서
- getter로 가져와서 변경하는 방식은 응집성을 떨어뜨린다
- 가급적 setter 사용 금지
Java
- 자바의 기본 자료형의 종류
- 논리 자료형
- boolean
- 문자 자료형
- char
- 정수 자료형
- byte, short, int, long
- 실수 자료형
- float, double
- 논리 자료형
- 객체란 무엇이며 객체 지향이란 무엇인가? (4가지특징과 5대원칙 설명)
- 객체
- 클래스에 정의된 내용대로 메모리에 생성된 것
- 객체지향
- 프로그래밍에서 필요한 데이터를 추상화시켜 상태와 행위를 가진 객체를 만들고 그 객체들 간의 유기적인 상호작용을 통해 로직을 구성하는 프로그래밍 방법
- 4가지 특징
- 추상화
- 실제 세상을 객체화하는 것이 아닌, 필요한 정보만을 중심으로 간소화하는 것
- 캡슐화
- 객체에 필요한 데이터나 기능을 책임이 있는 객체에 그룹화시켜주는 것
- 상속
- 상위 클래스의 기능을 하위 클래스에서도 사용할 수 있게 해주는 것
- 다형성
- 객체간의 관계를 유연하게 해주는 것
- 객체지향 주요특징 4가지
- 추상화
- 5대 원칙
- 단일 책임 원칙(Single Responsibility Principe)
- 하나의 클래스는 하나의 책임만 가져야 한다
- 변경사항이 있을 때, 어플리케이션의 파급 효과가 적으면 SRP 원칙을 잘 따른 것이다
- 개방 폐쇄 원칙(Open Closed Principle)
- 높은 응집도와 낮은 결합도
- 높은 응집도
- 하나의 모듈/클래스가 하나의 책임에만 집중되어있다는 뜻
- 낮은 결합도
- 하나의 변경이 발생할 때 다른 모듈과 객체로 변경에 대한 요구가 낮은 상태
- 리스코프 치환 원칙(Liskov Substitution Principle)
- 객체는 프로그램의 정확성을 깨지 않으면서 하위 타입의 인터페이스로 바꿀 수 있어야 한다
- 인터페이스 분리 원칙(Interface Segragation Principle)
- 범용 인터페이스 하나보다는 특정 클라이언트를 위한 여러 개의 인터페이스 분리가 더 좋다
- 의존관계 역전 원칙(Dependency Inversion Principle)
- 프로그래머는 구체화가 아니라 추상화에 의존해야 한다.
- 인터페이스에 의존하라는 의미이다.
- 단일 책임 원칙(Single Responsibility Principe)
- 객체
- 객체지향을 사용한 이유
- 객체지향을 사용하면 코드의 중복을 어느정도 높일 수 있고, 코드의 역할 분담을 좀 더 확실하게 할 수 있어서 가독성을 높일 수 있다
- 오버로딩과 오버라이딩의 차이
- 오버로딩(Overloading)
- 같은 이름의 메소드를 여러 개 가지면서 매개변수의 유형과 개수가 다르도록 정의하는 기술
- 오버라이딩(Overriding)
- 상위 클래스가 가지고 있는 메소드를 하위 클래스가 재정의해서 사용하는 기술
- 오버로딩(Overloading)
- 기본 생성자는 언제 필요한가?
- 항상 필요하다. 객체는 생성자 없이 생성이 불가능하다. 생성자를 아무것도 안 적은 채 컴파일을 하면 기본 생성자가 자동으로 생성된다. 사용자 정의 생성자를 만들어줬을 때 기본 생성자를 직접 적어줘야 한다. 컴파일러가 자동으로 생성해주지 않는다.
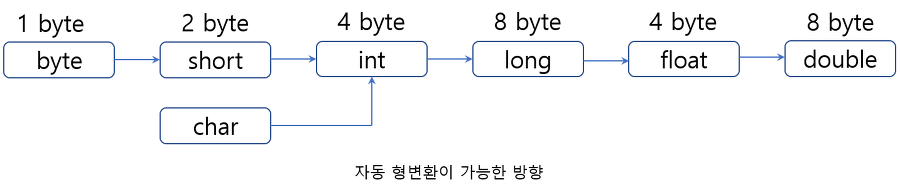
- 형변환이란?
- 형변환(캐스팅, casting)
- 변수 또는 상수의 타입을 다른 타입으로 변환하는 것
- 프로그램에서 값의 대입이나 연산을 수행할 때는 같은 타입끼리만 가능하다. 그래서 연산을 수행하기 전에 같은 타입으로 만들어야 하는데, 변수나 상수를 다른 타입으로 변환하는 것을 ‘형변환’이라고 한다
- 자동 형변환
- 개발자가 지정하지 않아도 자동으로 이루어진다
- 작은 그릇을 큰 그릇에 데이터를 옮겨담아야 손실 없이 그대로 보존된다
- 강제 형변환(명시적 형변환)
- 개발자가 명시해야만 이루어진다
- 큰 데이터 타입에서 작은 데이터 타입으로 옮길 때 데이터의 손실이 발생할 수도 아닐수도 있다. 데이터의 손실이 일어난다면 정확한 연산을 할 수없기 때문에 강제 형변환 시 주의해야 한다.
- 형변환(캐스팅, casting)
- Static이란?
- static 키워드 사용
- 메모리에 한 번 할당되어 프로그램이 종료될 때 해제되는 것
- 우리가 만든 클래스는 메모리 중 static 영역에 생성되고, new 연산자를 통해 생성한 객체는 heap 영역에 생성된다
- heap 영역의 메모리는 garbage collector를 통해 수시로 관리를 받는다
- static 영역의 메모리는 모든 객체가 공유하는 메모리라는 장점을 갖지만, garbage collector의 관리 영역 밖이기 때문에 static을 자주 사용하면 프로그램의 종료 시까지 메모리가 할당된 채로 존재하므로 시스템에 악영향을 주게 된다
- static 변수
- 메모리에 고정적으로 할당되어, 프로그램이 종료될 때 해제되는 변수
- 메모리에 한 번 할당되므로 여러 객체가 해당 메모리를 공유하게 된다.
- static 메소드
- 객체의 생성 없이 호출이 가능하고, 객체에서는 호출이 불가능하다
- 예: java.util.Math
- static 키워드 사용
- 참조자료형이란?
- 주소를 가지고 있는 변수
- 기본 자료형을 제외한 나머지 타입은 모두 참조 자료형 변수이다
- 참조 자료형은 객체의 주소를 저장한다
- 자바 ! 변수 (기본자료형, 참조자료형, 자료의 형변환)
- 어노테이션이란?
- 어노테이션
- 자바에서 사용될 때의 어노테이션은 코드 사이에 주석처럼 쓰여서 특별한 의미/기능을 수행하도록 하는 기술이다. 즉, 프로그램에게 추가적인 정보를 제공해주는 메타데이터(meta data: 데이터를 위한 데이터)라고 볼 수 있다
- 어노테이션의 용도
- 컴파일러에게 코드 작성 문접 에러를 체크하도록 정보 제공
- 소프트웨어 개발툴이 빌드나 배치 시 코드를 자동으로 생성할 수 있도록 정보 제공
- 실행 시(런타임 시) 특정 기능을 실행하도록 정보 제공
- 어노테이션
- 인스턴스 변수와 클래스 변수에 차이
- 클래스 변수(Static 멤버)
- 클래스 내에 static 키워드로 선언된 변수
- 처음 JVM이 실행되어 클래스가 메모리에 올라갈 때부터 프로그램이 종료될 때까지 유지
- 클래스가 여러 번 생성되어도 static 변수는 딱 한번만 생성
- 동일한 클래스의 모든 객체들에 의해 공유된다
- 인스턴스 변수(Non-static 멤버)
- 클래스 내에 선언된 변수
- 객체 생성 시 매번 새로운 변수 생성
- 클래스 변수와 달리 공유되지 않는다
- 클래스 변수(Static 멤버)
- Final 키워드란? 그리고 언제 사용하는지
- final
- 변수에 사용되면 값을 변경할 수 없는 상수가 되고, 메소드에 사용되면 오버라이딩을 할 수 없게 되고, 클래스에 사용되면 자신을 확장하는 자손 클래스를 정의하지 못하게 된다
- [Java] final 키워드 간단하게 정리하기
- 언제 사용하는지?
- 불변 객체에 정의 후 값을 재할당하지 않을 때 사용
- 상수(const)에서 많이 사용
- java final 의 의미, 언제 사용할까?
- final
- non-static멤버와 static 멤버의 차이
- 인스턴스 변수와 클래스 변수에 차이와 동일
- 컬렉션 프레임워크 List말고 다른 인터페이스는 뭐가 있는가?
- collection framework
- 다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합
- java의 interface를 사용하여 구현된다
- 주요 인터페이스
- List 인터페이스
- Collection 인터페이스를 상속받는다
- 순서가 있는 데이터의 집합으로, 데이터의 중복을 허용한다
- Set 인터페이스
- Collection 인터페이스를 상속받는다
- 순서가 없는 데이터의 집합으로, 데이터의 중복을 허용하지 않는다
- Map 인터페이스
- 구조상의 차이로 인해 Collection 인터페이스를 상속받지 않고 별도로 정의되었다
- 키와 값의 한 쌍으로 이루어지는 데이터의 집합으로, 순서가 없다
- 키의 중복은 허용하지 않지만, 값은 중복될 수 있다
- List 인터페이스
- collection framework
- List인터페이스의 구현체 두 가지
- Vector 클래스
- ArrayList와 동일한 내부구조를 가진다
- 동기화된(synchronized) 메소드로 구성되어 있다

- 멀티 스레드 환경에서 안전하게 객체를 추가/삭제할 수 있다. 즉, 스레드에 안전하다(Thread Safe)라고 말한다
- 동기화 되어있기 때문에 ArrayList보다는 객체를 추가/삭제하는 과정이 느릴 수 밖에 없다
-
// String 객체를 관리하는 Vector 객체 생성 List<String> list = new Vector<>(); // 객체 추가 list.add("hello"); // 객체 제거 list.remove(0);
- LinkedList 클래스
- ArrayList에는 내부 배열에 객체를 저장해서 인덱스로 관리하지만, LinkedList는 인접 참보를 링크해서 체인처럼 관리한다
- LinkedList에서 특정 인덱스의 객체를 제거하게 되면 제거되는 인덱스의 앞 뒤 링크만 변경되고 나머지 링크는 변경되지 않는다
-
Java 리스트(List) 컬렉션 종류 ArrayList, Vector, LinkedList// LinkedList 객체 생성 List<String> list = new LinkedList<>();
- Vector 클래스
- 자바의 Array와 ArrayList의 차이
-
Array ArrayList 사이즈 초기화 시 고정
int[] myArray = new int[6];초기화 시 사이즈를 표시하지 않음. 유동적
ArrayList<Integer> myArrayList =
new ArrayList<>();속도 초기화 시 메모리에 할당되어 속도가 빠르다 추가 시 메모리를 재할당하여 속도가 느리다 변경 사이즈 변경 불가 추가/삭제 가능
add(), remove()다차원 가능
int[][][] multiArray = new int[3][3][3];불가능
-
[JAVA] Array와 ArrayList 차이와 사용법
- Array나 List를 그대로 쓰면 되는데 왜 굳이 Stack이나 Queue로 쓰는지?
- 데이터를 효율적으로 저장하고 관리해서 메모리를 효율적으로 사용하기 위해(효율성과 관리의 편의성 때문)
- [TIL] 자료구조, Stack, Queue
- Exception 클래스가 있는데 Exception은 크게 두 가지로 나뉜다 이 두 가지는 무엇인가?
- compile checked Exception 계열
- 컴파일 시 예외처리 유무를 검사하는 클래스 계열
- IOException, SQLException 등
- 예외처리 필수. 반드시 명시적으로 예외처리를 해야한다
- compile unchecked Exception 계열
- 컴파일 시 예외처리 유무를 검사하지 않는 클래스 계열
- 예외처리 선택. 대부분 발생되는 예외가 개발자의 부주의한 코드 작업으로 발생하기 때문에 컴파일 시 예외처리 유무를 검사하지 않는다
- 예: 값을 0으로 나누기, null값으로 메소드 호출, 배열의 크기보다 큰 인덱스 값으로 접근
- 프로그램의 종료로 이어진다
- compile checked Exception 계열
- Exception과 Error의 차이
- Exception
- 실행 도중 중단될 정도로 큰 문제가 아닐 때 발생
- Checked Exception, Unchecked Exception 두 종류의 예외가 존재한다
- Checked Exception
- 실행하기 전에 예측 가능한 SQLException이나 FileNotFoundException 등을 말한다
- Unchecked Exception
- 실행하고 난 후에 알 수 있는 ArrayIndexOutOfBoundException, NullPointerException 등을 말한다
- Error
- 런타임에서 실행 시 발생
- 전부 예측 불가능한 Unchecked Error에 속한다
- Exception과 다르게 에러가 발생할 경우 코드를 고치지 않고서는 해결 불가능
- 예: StackOverflowError, OutOfMemoryError
- Exception
- 리터럴 (Literal) 이란?
- 프로그램에서 직접 표현한 값
- 소스코드의 고정된 값을 대표하는 용어
- 정수 리터럴
- 10진수(ex: 15), 8진수(ex: 015), 16진수(ex: 0x15), 2진수(ex: 0b0101)
- 실수 리터럴
- 소수점 형태나 지수 형태로 표현한 값
- 숫자 뒤에 f(float)나 d(double)을 명시적으로 붙이기도 한다
- float같은 경우는 f를 꼭 붙여야 하고 double은 생략 가능하다
float h = 0.1234f;double i = .1234D;
- 문자 리터럴
- 단일 인용부호(’’)로 문자를 표현한다
char a = 'H';char b = "한";char c = \uae00;(유니코드값) (\u다음에 4자리 16진수로, 2바이트의 유니코드(Unicode))
- 문자열 리터럴
- 문자열은 기본타입이 아니다.
- ( " " )로 문자열을 표현한다
String lter = "JAVA"; lter + 26 = "lter26"
- 논리 타입 리터럴, 외 리터럴
- boolean 타입 변수에 치환하거나 조건문에 이용
boolean a = true; boolean b = 10 > 0; (여기선 b값이 true) boolean c = 0; (C와 달리 boolean 타입으론 1,0을 참,거짓으로 사용 불가) - null 리터럴은 레퍼런스에 대입해서 사용한다. 기본 타입에는 사용이 불가하고 String같은 경우에는 사용 가능하다.
-
int a = null;(에러) String str = null; str = "JAVA" - [JAVA]자바_리터럴(literal)이란?
- String의 특징
- 문자열을 만들 때 두 가지 방법
- 문자열 리터럴을 지정하는 방법
- String str1 = "abc" ; String str2 = "abc";
- String 클래스의 생성자를 사용해서 만드는 방법
- String str3 = new String("abc"); String str4 = new String("abc");
- equals(String s)를 사용했을 때는 두 문자열의 내용("abc")을 비교하기 때문에 두 경우 str1.equals(str2)과 str3.equals(str4)는 모두 true를 갖는다.
- 그러나 String 클래스의 생성사를 이용한 String인스턴스의 경우에는 new연산자에 의해서 메모리할당이 이루어지기 때문에 항상 새로운 String인스턴스가 생성된다.

- 문자열 리터럴을 지정한 방법에서 str1 과 str2 변수는 같은 주소 0x100(abc주소)를 가리키고 있기 때문에 str1==str2 경우에도 true가 나오는것이다.
반면 str3과 str4는 각각 new 연산자로 인해 새로운 메모리가 각각 할당되게 되는것이다.
- 문자열 리터럴을 지정하는 방법
- 문자열을 만들 때 두 가지 방법
- 객체와 클래스란 ?
- 클래스
- 객체를 정의해 놓은 것, 객체의 설계도 또는 틀
- 객체를 생성하는 데 사용
- 객체
- 실제로 존재하는 것, 사물 또는 개념
- 객체가 가지고 있는 기능과 속성에 따라 용도가 달라진다
- 클래스
- 생성사 주입과 필드 주입의 차이(스프링인데?)
- 필드 주입은 빈을 먼저 생성한 후에 의존성 주입을, 생성자 주입은 빈을 생성할 때 의존성 주입을 하게 된다.
- 생성자 주입을 사용하면 객체 변이 방지, 순환 참조 조기 발견, 테스트 코드 작성에 유리한 등의 이점이 있고, lombok을 사용하면 필드 주입과 비교하여도 코드를 깔끔하게 작성할 수 있다.
- 필드 주입과 생성자 주입
- 접근제어자에는 무엇이 있으며 각각의 차이
private: 같은 클래스 내에서만 접근 가능default: 같은 패키지 내에서만 접근 가능protected: 같은 패키지 내에서, 그리고 다른 패키지의 자손 클래스에서 접근 가능public: 접근 제한이 전혀 없다.- [JAVA] 접근제어자 (Access Modifier)
'TIL' 카테고리의 다른 글
| [TIL] 2022.01.04 면접 (0) | 2022.01.05 |
|---|---|
| [TIL] 2022.01.03 스프링 기초 공부 (0) | 2022.01.03 |
| [TIL] 2022.01.01 새해 (0) | 2022.01.01 |
| [TIL] 2021.12.31 기술면접 질문 정리 - JPA (0) | 2022.01.01 |
| [TIL] 2021.12.30 면접에 대한 무서움 (4) | 2021.12.30 |